

In this
N+1 Problem
Imagine that you’re developing a blog. Your server should provide GraphQL API so that your client app written in React, Vue or Angular can consume it and show some data to the user.
You have a couple of simple models:
# blog/models.py
from django.db import models
class Article(models.Model):
title = models.CharField(max_length=255)
body = models.TextField()
def __str__(self):
return self.title
class Comment(models.Model):
article = models.ForeignKey(
Article,
related_name='comments',
on_delete=models.CASCADE,
)
text = models.TextField()
def __str__(self):
return self.text
The client should be able to send a query for fetching a list of all blog articles and a list of comments related to each article:
query {
articles {
edges {
node {
title
body
comments {
text
}
}
}
}
}
If you have already played a little bit with Graphene Django, you can implement this API without breaking a sweat:
# gql/schema.py
from graphene import List, ObjectType, Schema
from graphene_django import DjangoConnectionField, DjangoObjectType
from blog.models import Article, Comment
class CommentType(DjangoObjectType):
class Meta:
model = Comment
only_fields = ('text',)
class ArticleType(DjangoObjectType):
comments = List(CommentType)
class Meta:
model = Article
only_fields = ('title', 'body')
use_connection = True
def resolve_comments(root, info, **kwargs):
return root.comments.all()
class Query(ObjectType):
articles = DjangoConnectionField(ArticleType)
def resolve_articles(root, info, **kwargs):
return Article.objects.all()
schema = Schema(query=Query)
When we send a query to the API, we will get exactly what we need:
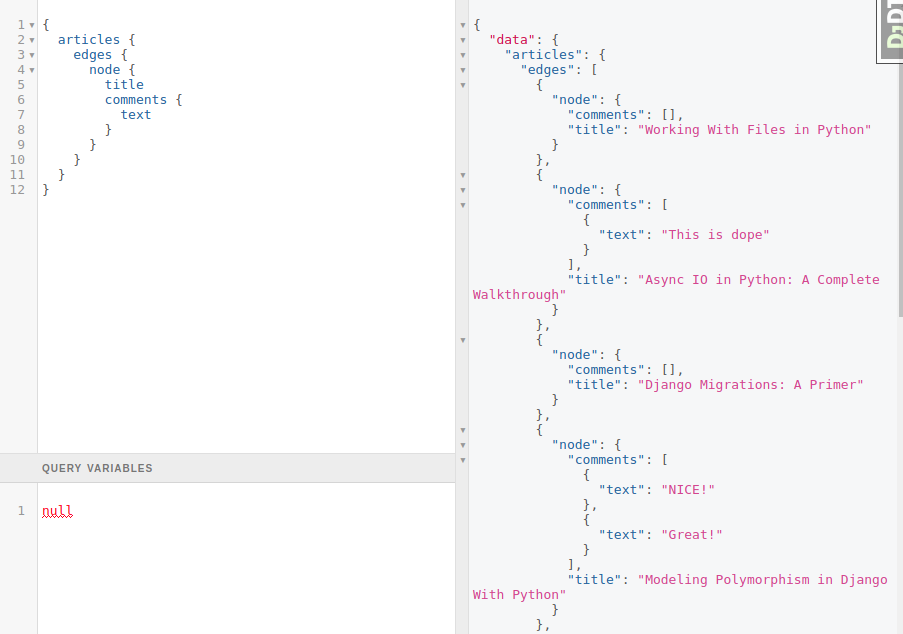
But there is one big problem that isn’t obvious because everything worked and we didn’t get any errors when we tried to make a request to the API.
If you install
The problem lies in this part of code:
class ArticleType(DjangoObjectType):
comments = List(CommentType)
...
def resolve_comments(root, info, **kwargs):
return root.comments.all()
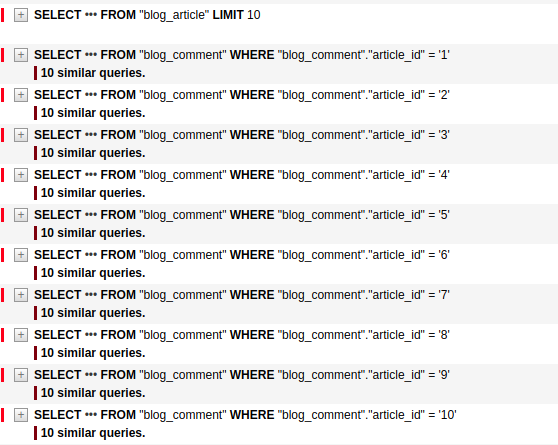
Inside of resolve_comments function we make a separate SQL query for fetching all comments related to the article. But resolve_comments is going to be called once for each article. So, if we have 10 articles, in order to get all required information, we need to send 1 SQL query for fetching a list of articles and 10 additional queries for fetching a list of comments for each article.
This problem called N+1 Problem. Now I’m going to show you how to solve it.
Solving N+1 Problem using DataLoaders
As you can see from the screenshot above, in order to fetch the comments we’ve sent 10 SQL queries:
SELECT * FROM "blog_comment" WHERE "blog_comment"."article_id" = '1' SELECT * FROM "blog_comment" WHERE "blog_comment"."article_id" = '2' SELECT * FROM "blog_comment" WHERE "blog_comment"."article_id" = '3' SELECT * FROM "blog_comment" WHERE "blog_comment"."article_id" = '4' SELECT * FROM "blog_comment" WHERE "blog_comment"."article_id" = '5' SELECT * FROM "blog_comment" WHERE "blog_comment"."article_id" = '6' SELECT * FROM "blog_comment" WHERE "blog_comment"."article_id" = '7' SELECT * FROM "blog_comment" WHERE "blog_comment"."article_id" = '8' SELECT * FROM "blog_comment" WHERE "blog_comment"."article_id" = '9' SELECT * FROM "blog_comment" WHERE "blog_comment"."article_id" = '10'
But can we somehow make it more efficient and instead of sending those 10 queries, send only 1 query? Like this one:
SELECT * FROM "blog_comment" WHERE "blog_comment"."article_id" IN ('1', '2', '3', '4', '5', '6', '7', '8', '9', '10')
Yes, we can. And DataLoaders will help us with that.
DataLoaders allow you to batch and cache data per request. Probably sounds confusing. So let’s get back to our example with articles and comments. resolve_comments function immediately sends a query to the database in order to get a list of comments:
class ArticleType(DjangoObjectType):
comments = List(CommentType)
...
def resolve_comments(root, info, **kwargs):
return root.comments.all()
Instead of getting a list of comments related to one particular article, we could collect all article ids and after some time, when all of the article ids were batched together, we could get comments for all articles at once.
This is what DataLoader does. It collects a list of keys and then calls a batch loading function which accepts a list of keys and returns a Promise which resolves to a list of values:
# gql/loaders.py
from collections import defaultdict
from promise import Promise
from promise.dataloader import DataLoader
from blog.models import Comment
class CommentsByArticleIdLoader(DataLoader):
def batch_load_fn(self, article_ids):
comments_by_article_ids = defaultdict(list)
for comment in Comment.objects.filter(article_id__in=article_ids).iterator():
comments_by_article_ids[comment.article_id].append(comment)
return Promise.resolve([comments_by_article_ids.get(article_id, [])
for article_id in article_ids])
There are a few constraints for values that should be met:
- The list of values must be the same length as the list of keys.
- Each index in the list of values must correspond to the same index in the list of keys.
This is what batching is, but what about caching? Caching is much simpler. If we load the same key two times, we’re only going to request it once. That’s it.
And the last important thing you need to know is that each DataLoader instance is created when a request begins, it’s only responsible for batching and caching relative to this single request. When the request ends, the DataLoader instance will be garbage collected.
Actually, you can serve multiple requests with one DataLoader instance if you want, but it’s not recommended.
Ok. That’s interesting. But how to use the DataLoader that we have just created?
We can create a custom GraphQL view and put the instance of DataLoader in the context:
# gql/views.py
from django.utils.functional import cached_property
from graphene_django.views import GraphQLView
from gql.loaders import CommentsByArticleIdLoader
class GQLContext:
def __init__(self, request):
self.request = request
@cached_property
def user(self):
return self.request.user
@cached_property
def comments_by_article_id_loader(self):
return CommentsByArticleIdLoader()
class CustomGraphQLView(GraphQLView):
def get_context(self, request):
return GQLContext(request)
After we replace GraphQLView in urlpatterns with CustomGraphQLView:
urlpatterns = [
...
path('graphql/', CustomGraphQLView.as_view(graphiql=True)),
]
We should be able to call the loader in resolve_comments function:
# gql/schema.py
...
class ArticleType(DjangoObjectType):
comments = List(CommentType)
...
def resolve_comments(root, info, **kwargs):
# return root.comments.all()
return info.context.comments_by_article_id_loader.load(root.id)
...
So now, when we send a query to the API we will only make 1 SQL query for fetching comments instead of 10:

Conclusion
DataLoaders is a beautiful tool that helps us to make our application more efficient by using two techniques: batching and caching. With batching we decrease the amount of requests to the database by grouping multiple requests into one batch request. With caching we avoid requesting the database at all.
If you got lost somewhere during reading the article, I’ve uploaded the source code on GitHub. It should help.
Now your database can chill because it doesn’t suffer from a lot of unnecessary queries anymore:

Hi.
I was wondering how you integrate GraphiQL with django-debug-toolbar?
Hi, it works without any integration. But it works only when you reload the page. If you just click on “Execute Query” button in GraphiQL, it won’t work. You need to write query and then reload the page.
Hi,
Great article. does this mean we need to build 2,500 loaders for my 500-model db? Let’s say, we need to resolve comments by article. Yeah, and also reverse that, resolve articles by comment.
Good question. As far as I know, yes.
Hi! Fine article.
But there is a little problem with get_context method. GraphQLView returns request object by default, but you didn’t add other request attributes to GQLContext object.
It creates a lot of bugs with request attributes. That’s why I’ve copied all attributes of request object to GQLContext object.
Is there another good solution?
I added the loaders to the request object instead. Something like this:
https://gist.github.com/mvmocanu/094679512dbc9c9cb2a7d07746d70bda
Nice. Thanks
Unfortunately you are loosing caching with this solution. (the @cached_property decorator)
This is great, thanks.
Any thoughts on maintaining the filter_fields attribute of a child node? For example if we wanted to filter comments by an ‘approved’ attributed for logged in vs. logged out users. I’m not entirely sure how that would work.
@exis
You could dynamically create a loader of this type by generating the loader something like this? https://gist.github.com/kayluhb/4e06ab4830e29fadc89bf452a7d4d2cb
Seems a little excessive looping more than once can this just return dict.values() instead of a double loop.
FROM
“`
…
comments_by_article_ids = defaultdict(list)
for comment in Comment.objects.filter(article_id__in=article_ids).iterator():
comments_by_article_ids[comment.article_id].append(comment)
return Promise.resolve([comments_by_article_ids.get(article_id, [])
for article_id in article_ids])
“`
TO
“`
comments_by_article_ids = defaultdict(list)
for comment in Comment.objects.filter(article_id__in=article_ids).iterator():
comments_by_article_ids[comment.article_id].append(comment)
return Promise.resolve(list(comments_by_article_ids.values()))
“`
Sorry but i have an error:
AttributeError: ‘GQLContext’ object has no attribute ‘META’
Why?
Please help me
thanks
I have the same error: AttributeError: ‘GQLContext’ object has no attribute ‘META’